Abstract: In order to solve the contradiction of small storage space and large amount of GPS positioning data in embedded GPS vehicle systems, according to the characteristics of GPS positioning data, an improved nibble compression algorithm dedicated to GPS fixed data compression is proposed. This algorithm is an improved algorithm based on the original nibble compression algorithm. After actual testing, the compression ratio can reach 50%. If the compression preprocessing is also included in the algorithm, the total compression ratio can reach more than 80%, which saves a lot of storage resources for the vehicle-mounted system. In addition, it also shortens the occupancy time of the GSM channel, which greatly eases the pressure of uploading data to the control and dispatch center.
The embedded GPS vehicle-mounted system is small in size and does not have a hard disk and other devices with large storage capacity. The system programs and application programs are generally installed in FLASH or ROM. Because the price of storage media such as FLASH or ROM is very expensive compared to hard disks and optical disks widely used on desktop computers, when developing software products for embedded systems, the storage space occupied by the software must be limited to a certain range Inside.
During the development of GPS vehicle systems,  The main problem to be solved is: in order to achieve self-navigation, the vehicle-mounted system must store a large amount of GPS positioning data (about 6MB per day); the second is that these data must also be uploaded to the control and dispatch center through the GSM channel (if sent via SMS , 160B each time, you need to upload 6 times per minute). Undoubtedly, data compression is an effective way to fully utilize the existing resources of the system from the perspective of software without increasing the cost of hardware.
The main problem to be solved is: in order to achieve self-navigation, the vehicle-mounted system must store a large amount of GPS positioning data (about 6MB per day); the second is that these data must also be uploaded to the control and dispatch center through the GSM channel (if sent via SMS , 160B each time, you need to upload 6 times per minute). Undoubtedly, data compression is an effective way to fully utilize the existing resources of the system from the perspective of software without increasing the cost of hardware.
There are many types of data compression methods, which can be divided into lossless compression and lossy compression. Lossless compression utilizes statistical redundancy of data for compression. The theoretical limit of data statistical redundancy is generally 2: 1 to 5: 1. This type of method is widely used for the compression of text data, programs, and image data for special applications (such as fingerprint images, medical images, etc.). Lossy compression methods take advantage of the insensitivity of human vision to certain frequency components in images, allowing some information to be lost during compression. Although the original data cannot be completely recovered, the lost part has a smaller impact on understanding the original image, but in return for a much larger compression ratio. Lossy compression is widely used to compress voice, image, and video data.
At present, there are many compression algorithms, but they cannot be directly used in embedded systems. This is entirely determined by the characteristics of embedded systems. First, the data compression method used in embedded systems should be a lossless compression method. Secondly, the compression code and the information code required for decoding must be short enough, otherwise the meaning of compression will be lost. In addition, the data compression of embedded systems must be combined with the characteristics of specific data formats in order to further improve the data compression ratio. In addition to this, the start-up and execution of current compression programs must be interfered with manually and cannot be executed automatically because they are designed for file systems, and data compression for embedded systems must be able to be executed automatically.
1 GPS data format
GPS OEM board consists of inverter, signal channel,  Microprocessor and storage unit. There are many types of GPS OEM boards with different performances, but most of them use the NMEA-0183 communication standard format developed by the National Marine Electronics Association. This system chooses SiRFstarII OEM board of American SiRF company. The input and output of the statements of SiRFstarII OEM board are completed through the RS232 serial interface. The data format of the communication port should be set to 8 data bits, 1 start bit and 1 stop bit. The check mode is selected as no parity Verify that the baud rate is set to 4800 baud. The output data of the NMEA-0183 communication standard uses ASCII code, and its content contains information such as latitude, longitude, altitude, speed, date, time, course, and satellite status. There are six kinds of sentences, including GGA, GLL, GSA, GSV , RMC and VTG. For different purposes, the selected sentence records are also different. For example, users of embedded GPS car systems only care about their date and time, correction, and surface speed information, so they can only choose RMC to record sentences. A $ GPRMC statement includes 13 records: statement identifier, world time, positioning status, latitude, latitude bearing, longitude, longitude bearing, ground speed, ground route, date, magnetic declination, checksum, and end marker, which totals Occupies 70 bytes (which also includes 11 commas used to separate records), for example:
Microprocessor and storage unit. There are many types of GPS OEM boards with different performances, but most of them use the NMEA-0183 communication standard format developed by the National Marine Electronics Association. This system chooses SiRFstarII OEM board of American SiRF company. The input and output of the statements of SiRFstarII OEM board are completed through the RS232 serial interface. The data format of the communication port should be set to 8 data bits, 1 start bit and 1 stop bit. The check mode is selected as no parity Verify that the baud rate is set to 4800 baud. The output data of the NMEA-0183 communication standard uses ASCII code, and its content contains information such as latitude, longitude, altitude, speed, date, time, course, and satellite status. There are six kinds of sentences, including GGA, GLL, GSA, GSV , RMC and VTG. For different purposes, the selected sentence records are also different. For example, users of embedded GPS car systems only care about their date and time, correction, and surface speed information, so they can only choose RMC to record sentences. A $ GPRMC statement includes 13 records: statement identifier, world time, positioning status, latitude, latitude bearing, longitude, longitude bearing, ground speed, ground route, date, magnetic declination, checksum, and end marker, which totals Occupies 70 bytes (which also includes 11 commas used to separate records), for example:
$ GPRMC, 121530.998, A, 4000.0162, N, 11619.5476, E, 0.00,240.81,160102 ,, * 3B
It can be seen that the data stream received from the SiRFstarII OEM board is a text string. According to the characteristics of the GPS data format, this design intends to use the nibble method to complete the compression and decompression tasks. This method belongs to the lossless compression technology, and its principle is to remove the redundant bits in the byte, so as to achieve the purpose of compression. However, this method is only suitable for the compression of pure digital text files. Obviously, GPS positioning data is not pure digital. You must also perform compression preprocessing before compression, and finally use the nibble compression algorithm to complete the data compression.
2 Compression preprocessing
Careful observation of the above data records shows that there is still a lot of redundancy in the data sections between the sentences. In addition, the information contained in these records has both English characters and numbers. For subsequent compression, the following pre-processing should be performed on each record in the statement:
â‘ Statement identification header (ID): Because the identification header of each statement is the same, the record segment belongs to redundant information and can be completely removed. When decompressing, add the identification header before each statement. 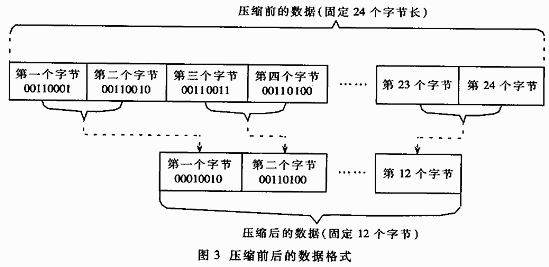
â‘¡ Universal Time (UTC): This information segment indicates the current world time in the format of hours, minutes, seconds, and milliseconds. It takes another 8 hours to convert to Beijing time. Since the location data of the vehicle-mounted system is collected in seconds, the data in the order of milliseconds is useless for this system and is redundant information. Since the world time is increased by 1 per second, the location data is also updated once per chairperson World time can be collected and recorded at the beginning of the program, and it can be restored according to the pointer value of the statement plus the start time during decompression, so after the first storage of the record segment, all the information in subsequent statements Is redundant information.
â‘¢Positioning state (A / V): Occupy 1 byte, no preprocessing. Because the vehicle system may not receive satellite signals (such as in a tunnel) where the positioning information is invalid, so although the probability of this field changing is small and it is not related to other information segments, it cannot be preprocessed here .
â‘£ Latitude: occupies 9 bytes without preprocessing.
⑤ Latitude: takes up 10 bytes, without preprocessing.
â‘¥Longitude indicator (E / W): occupies one byte, which indicates whether the longitude is east longitude or a match. Since this piece of information in each $ GPRMC sentence is East Path in China, it is redundant information, so the method of storing it once at the beginning of the program is also adopted.
⑦ Latitude indicator (N / S): occupies one byte, the information in this section of each $ GPRMC sentence is exactly the same, it is redundant information, and the processing method is the same as above.
⑧Ground speed: 4 bytes, no pre-processing.
⑨Date: takes up 6 bytes and displays in the format of day, month, year All the information in the sentence is abolished.
â‘©Checksum: takes up 3 bytes, the data will be discarded after verification, not retained and compressed.
The end meets 2 bytes and is only used to judge the effective data range of the statement. Other record segments are not retained and compressed regardless of the design of the system.
After the above compression preprocessing, four data records are retained, occupying a total of 24 bytes, as shown in Figure 1. 
3 Improved nibble compression algorithm
The compression of text data is lossless compression technology, that is, the restored file should be exactly the same as the source file. There are many ways to compress text files, such as HUFFMAN encoding, arithmetic encoding, and byte compression methods. They are all lossless compression methods, and they are all suitable for text data compression. The nibble compression method is designed for the characteristics of text data, mainly to remove the redundant bits in the bytes in the text, so as to achieve the purpose of reducing the storage space occupied by the data file. In data compression technology, in addition to compressing repeated characters, it can also be compressed according to the characteristics of the data itself. In a computer, any data is stored in a code. In some files, there may be some codes with certain similarities. We can perform specific operations according to the characteristics of the code to compress the similar parts of these data, or compress the characteristic parts of these data, nibble compression is Such a method. The nibble method is mainly used for the compression of pure digital text files, because the upper four bits of the ASCII code of the numbers 0-9 are the same and are redundant, so each number can be described by the lower four bits, that is, each The eight-bit encoding of bytes can be compressed into four-bit encoding, and the compression ratio can theoretically approach 50%.
As can be seen from Figure 1, the pre-processed data contains text bytes: "0 ~ 9" ten number symbols, "A", "V" two English capital letters and a decimal point ". "Symbol, a total of 13 characters. The upper four digits of the ASCII codes of "A", "V", and "." Are obviously different from those of digital bytes, and the nibble compression method cannot be simply applied. However, we know that the four-bit binary code can distinguish 16 states, which is enough to represent 13 different characters.
The compressed data coding table is like the comfort of Table 1. In order to make full use of the state in the coding table, two new characters "B" and "W" are added on the basis of the original 13 bytes, and their four-bit codes are 1101. And 1110. These two characters are used to record the statements discarded due to the error of the checksum in the compression preprocessing process. Because the time information of each sentence is discarded in the preprocessing stage, the time value should be restored when decompressing. Under normal circumstances, this value is determined according to the base of time plus the count value of the statement (since a statement is received every second, the statement count value is the time increment in seconds). When a sentence checksum error occurs, if the positioning is valid, the "A" character is not filled in the positioning status record, but the "B" character is filled; if the positioning is invalid, the "V" character is not filled. Instead, fill in the "W" byte. In the future decompression, if the "A" and "V" bytes are detected, the time is restored according to the normal algorithm; if the "B" and "W" characters are detected, the restoration is performed according to the normal algorithm In addition, seconds must be added to ensure that the time can be recovered correctly. This is because the "B" and "W" bytes indicate that the error in the previous statement has been discarded, and the compression of the statement is discontinuous. occur.
Table 1 Compression data encoding table
| Characters contained after preprocessing | ASCII code | Four-digit binary encoding | Remarks |
| 0 1 2 3 4 5 6 7 8 9 . A B V W | 00110000 00110001 00110010 00110011 00110100 00110101 00110110 00110111 00111000 00111001 00101110 01000001 01000010 01010110 01010111 | 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1101 1100 1110 | Positioning valid Positioning valid, seconds 1 Invalid positioning Invalid positioning, increment by 1 |
After conversion through this encoding table, the original 24 bytes of text data after compression preprocessing can be reduced by half (after compression, it is a fixed 12 bytes long), and the compression ratio is 50%. If the text data has not been preprocessed, the compression ratio can reach 80%.
It can be seen from Figure 2 that implementing the nibble compression algorithm needs to solve two problems: the first is the count of compressed objects; and the second is how to merge the lower bits of the two numbers into one byte. The latter problem only needs to specify the order of storing the four-digit encoding of odd-numbered characters and the four-digit encoding of even-numbered characters in the compressed bytes. The implementation of the program is very simple. Here we specify that the characters with odd numbers are placed in The upper four digits, the encoding of the even-numbered characters is placed in the lower four digits. Assuming that the first four bytes in the data stream before compression are "1, 2, 3, 4", the compressed data format is shown in Figure 3.
The first problem to be solved in nibble compression is the counting of compressed objects. There are two ways to solve this problem: one is the half-byte counter (Half-Byte Counter), and the other is the full-byte counter (Full -Byte Counter). Regardless of which method, they will occupy bytes, plus the compression flag will also occupy bytes, so it will affect the data compression ratio. The improved nibble compression algorithm completely solves this problem, because the data length of GPS positioning data after compression preprocessing is fixed 24 bytes long, not dynamically variable, so there is no need to solve the problem of counting compressed objects . Generally speaking, any kind of compression algorithm needs to use compression indicator characters to mark compressed data. The shorter the compression identifier, the better, because too long will affect the compression effect. However, since all characters in the GPS positioning data are encoded, there are no original characters (characters that are not compressed and output as they are when decompressed), so the compression mark can be omitted completely, which can further improve the data compression ratio. The block diagram of the compression preprocessing program and the improved nibble compression algorithm are shown in Figure 4. 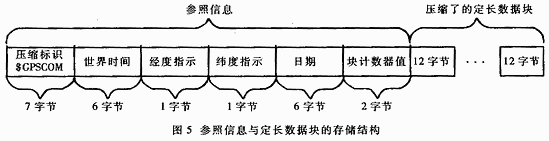
The compressed file includes important information required for decompression, and is composed of release parameter information and successively compressed fixed-length data blocks. The release reference information contains the time base information to be used for decompression. It can restore the time through the statement counter and the error code number. In addition, the release reference information also includes common information required by each fixed-length data block during decompression, such as E / W, N / S, and date. The format of the compressed file is shown in FIG. 5.
The compression of the embedded system is done automatically in real time without human intervention. The specific implementation method is through resident memory (in single-task operating system, such as DSP) or as a background task (in multi-task operating system, such Windows) Real-time compression or decompression of data.
Table 2 Test results of improved nibble compression algorithm
| Processing File size (B) | After pretreatment | Improved nibble compression | Compression ratio |
1035k = 69 & TImes; 15000 | 360KB + 23B 36KB + 23B 3.6KB + 23B | 180KB + 23B 18KB + 23B 1.8KB + 23B | 0.8260 0.8259 0.8239 |
The compression algorithm of GPS positioning data has actually been verified. The compression ratio decreases slightly as the compressed data decreases. This is because the proportion of reference information gradually increases as the compressed data decreases. However, it is shown that the use of this compression method in a vehicle-mounted system can not only save storage space, but also reduce channel occupation time and improve data security. Since the compression program is written for the GPS data format, the compression ratio is large but the versatility is not strong. Nevertheless, the program can be transplanted to other systems with slight modifications, because the specifications implemented by each GPS manufacturer are all implemented by GPS manufacturers are NMEA-0183, and the data output format is slightly different.
Car Vacuum Cleaner : this usb car vacuum cleaner can be used for cleaning car vent, dashboard, storage cabinet, sand, dust, paper, food debris, and so on. With blow and suction function, the handheld Mini Vacuum Cleaner can clean every small space inside the car very well. And the Portable Vacuum Cleaner body is very small, it can be stored in a small space in the car.
By the way, this Handheld Vacuum Cleaner is cordless Usb Vacuum Cleaner , power supplied by usb port, which is very easy and convenient to use.
Except for cleaning cars, this multifunctional wireless Small Vacuum Cleaner can be also used for cleaning hidden dirty of notebook keyboard, printer, pet food, office, kitchen table, or other small household appliances.
Car Vacuum Cleaner
Mini Vacuum Cleaner,Portable Car Vacuum,Handheld Vacuum For Car,Portable Car Vacuum Cleaner
SHENZHEN HONK ELECTRONIC CO., LTD , https://www.honktech.com