The recommendation system is one of the most successful and widely used applications of machine learning technology in the enterprise.

Machine Learning for Recommender systems — Part 1 (algorithms, evaluation and cold start)
introduction
You can apply recommendation systems in scenarios where many users interact with the project.
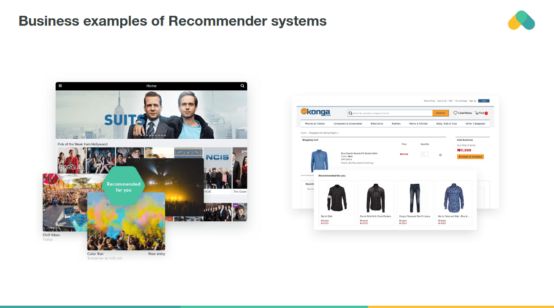
You can find large recommendation systems in retail, video on demand, or music streaming. To develop and maintain such a system, companies often need a group of expensive data scientists and engineers. This is why even big companies like the BBC have decided to outsource their referral services.

Our company is headquartered in Prague and has developed a general-purpose automated recommendation engine that can adapt to business needs in multiple areas. Our engines have been used by hundreds of companies around the world.

Surprisingly, news or video recommendations for the media, product recommendations or personalized recommendations in travel and retail can all be handled through similar machine learning algorithms. In addition, these algorithms can also be adjusted using our unique query language in each recommendation request.
algorithm

Machine learning algorithms in recommendation systems are generally divided into two categories: content-based recommendation methods and collaborative filtering methods, although modern recommenders combine these two methods together. The content-based approach is based on the similarity and collaboration methods of project attributes and the similarity is calculated from interactions. In the following we discuss collaborative filtering methods that allow users to discover new content that is different from those viewed in the past.

The collaborative filtering method works with the interaction matrix. When the user provides explicit scoring of the item, this interaction matrix can also be called a scoring matrix. The task of machine learning is to learn a function that can predict the effect of the project on each user. The matrix is ​​usually large, very sparse, and most of the values ​​are lost.

The simplest algorithm is to calculate the cosine or other related similarity of a row (user) or column (item), and recommend the items that k nearest neighbors like.

The matrix factorization method tries to reduce the dimension of the interaction matrix and approximate it to two or more small matrices with k potential components.

By multiplying the corresponding rows and columns, you can predict the project's score based on the user. Training errors can be obtained by comparing non-null scores with predictive scores. It is also possible to adjust the training loss by adding penalty items and keeping the potential vector low.

The most popular training algorithm is the stochastic gradient descent algorithm, which minimizes descent losses by gradient updating the columns and rows of the pq matrix.

Alternatively, the matrix p and the matrix q may be iteratively optimized through a general least-squares step using an alternating least-squares method.

Association rules can also be used for recommendations. Items that are often consumed together are associated with the edges in the graphics. You can see a set of bestsellers (close-knit projects that almost everyone interacts with) and small, separate content clusters.

The rules mined from the interaction matrix should have at least some minimum support and confidence. The degree of support is related to the frequency of occurrence. For example, the bestseller has a high degree of support. High confidence means that rules will not be violated often.
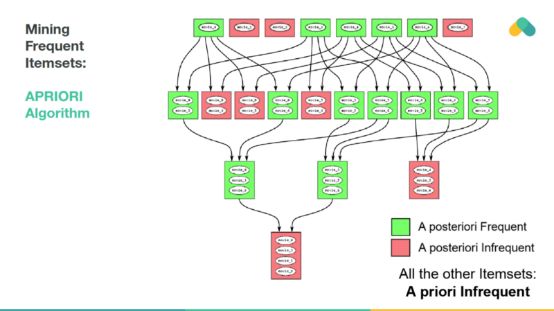
The size of mining rules is not large. The prior algorithm explores the state space of possible frequent itemsets and eliminates infrequent branches in the search space.

Frequent itemsets are used to generate rules that generate recommendations.

For example, we show the rules extracted from bank transactions in the Czech Republic. Nodes (interactions) are terminals and edges are frequent transactions. You can recommend the relevant bank terminal based on past withdrawals/payments.
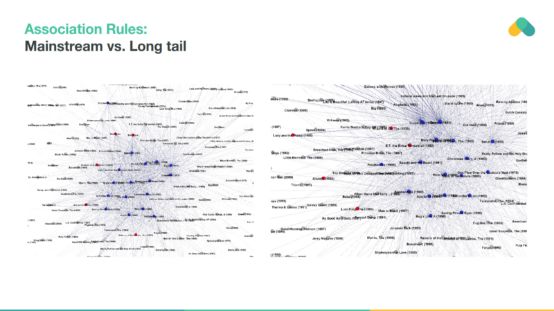
Punishing popular items and extracting long-tailed rules with less support can produce interesting rules that diversify recommendations and help discover new content.

Scoring matrices can also be compressed using neural networks. So-called self-encoders are very similar to matrix decompositions. Deep-seated auto-encoders with multiple hidden layers and nonlinearities are more powerful but harder to train. Neural networks can also be used to preprocess item attributes so that content-based methods and collaborative filtering methods can be combined.

The user-KNN Top-N recommendation pseudo code is given above.

Association rules can be mined by several different algorithms. Here we give the pseudo code for the Best-Rule recommendations.

The pseudo-code of the matrix factorization is given above.

In collaborative deep learning, the combination of project attributes and self-encoders simultaneously trains matrix factorization, of course, there are more algorithms available for recommendation. The next part of this article introduces some methods based on deep learning and reinforcement learning.
Recommendation System Evaluation
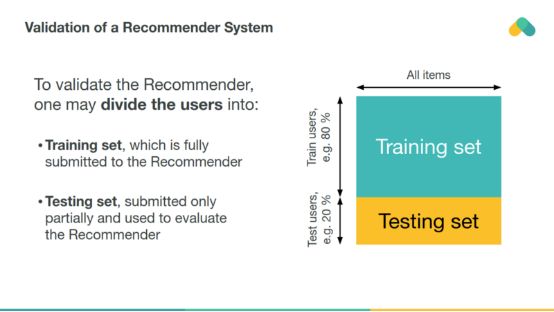
The recommender can perform a similar assessment with the classic machine learning model (offline assessment) on historical data.

Interactions between randomly selected test users are cross-validated to estimate the recommender's performance on unseen ratings.

Although many studies have shown that the mean square error (RMES) has poor ability to estimate online performance, it is still widely used.

A more practical off-line assessment measure is the percentage of recalled items (Recall) or Precision (Precision) to evaluate the correct recommendation items (excluding recommended items or related items). The DCG also takes into account the position of the hypothetical project when the logarithm of correlation declines.
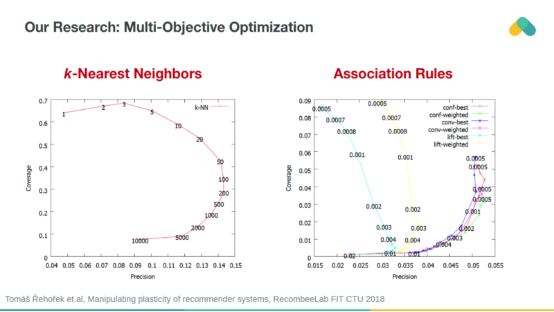
We can use additional metrics that are less sensitive to off-line data deviations. Catalog coverage and Recall or Precision can be used for multi-objective optimization. We introduce regularization parameters in all algorithms, allowing them to operate on plasticity and punishing recommendations for popular items.

Both Recall and Coverage should be maximized, thus promoting the recommendation system to be accurate and diversified, enabling users to explore new content.
Cold start and content based recommendations

Interactions are sometimes lost. Cold start products or cold start users do not have enough interaction to reliably measure their interaction similarity, so collaborative filtering methods cannot produce recommendations.
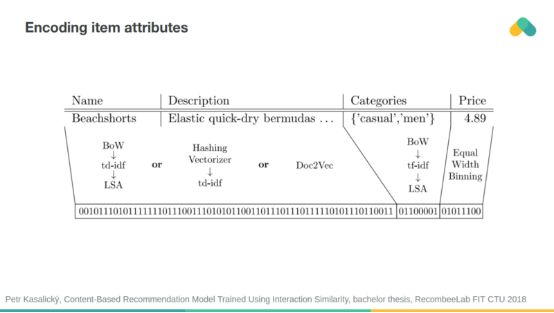
When considering the similarity of attributes, the cold start problem can be reduced. You can encode properties into binary vectors and provide systems for recommendation.
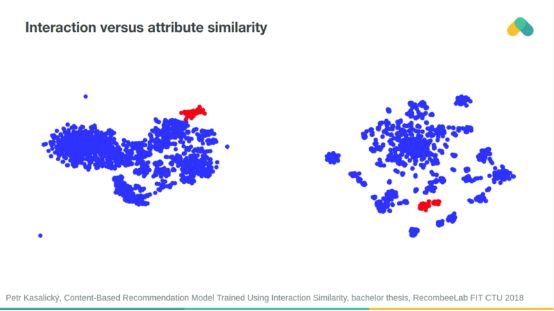
Project clustering based on interaction similarity and attribute similarity is often aligned.

You can use neural networks to predict interaction similarity from attribute similarity and vice versa.

There are many other ways that we can reduce cold start problems and improve the quality of recommendations. In the second part, we will discuss session based recommendation techniques, in-depth recommendation, integration algorithms, and automation that enable us to run and optimize thousands of different recommendation algorithms in production.
High temperature thermocouple slip ring with German and Japanese imports of key materials, can be used in high temperature environment rotate 360 degrees to transmit current and thermocouple signal, can be long-term stability in 100 ~ 250 ℃ high temperature environment, it is mainly used for hot roller, the high temperature environment, such as heating device, suffered long-term complex field practice test, transmission performance is stable and the quality.
High Temperature Slip Ring,Taidacent Slip Ring,Slip Ring Capsule,Fiber Brush Slip Ring
Dongguan Oubaibo Technology Co., Ltd. , https://www.sliprobs.com