The complexity of image processing algorithms is usually high, and calculations are relatively time-consuming. Utilizing the CPU's multi-threaded processing capabilities can greatly speed up the calculation speed. However, in order to ensure that the results of multithreaded processing are exactly the same as those of single-threaded processing, there are some special considerations for multithreaded computation of images.
The basic idea:
In order to allow multiple threads to process in parallel, it is well understood that the data processed by each of them cannot have intersections. The basic idea is to divide an image into multiple sub-blocks. Each sub-block data must have no intersection. Each thread processes one sub-block data and completes all sub-block processing results to form the final image.
First of all, the size of each sub-block is, of course, a problem that must be considered. Usually when the application performs a long time operation, the user should be informed in a suitable manner. Since we deal with image block processing, if the processing time of a single sub-block is short, then each time a sub-block has been processed, we can immediately display its corresponding processing result to the user. The user will see the processing results of the various parts of the image displayed continuously until the entire image is completed. To some extent this way is to inform the user that processing is in progress and to avoid the user having to wait too long in order to complete the entire image processing. From this point of view, if the sub-block size is taken too large, the calculation time of each sub-block will certainly increase accordingly, which is disadvantageous for the user to quickly display the partial processing results. However, if the sub-block is too small, the total number of sub-blocks will increase, which will definitely increase the thread overhead and other overhead (split image, allocate sub-block data, etc.), which is disadvantageous for the total calculation time. This is a trade-off issue that can be determined based on specific circumstances.
In addition, many image processing must consider the information in the pixel domain, so the processing of each sub-block cannot use only the content of this sub-block. Specifically, for pixels near the edge of the sub-block, some pixel information outside the sub-block needs to be taken into consideration, and calculations are added to ensure that the processing result of the corresponding pixel is correct. To be precise, if the radius of the field is r (for other areas that can be adjusted accordingly for square or circular fields), all the data required for sub-block processing is the range of r pixels extending outward from the sub-block.

The code in the extension is the size of the sub-block to expand around, in fact, the radius of the field r. pRect[i] is the size of the partitioned i-th sub-block. Height and Width are the height and width of the original image, and the extension sub-block naturally cannot exceed the size of the original image. Then the final rect1 is the scope of the field where the data needed for the calculation is located in the original image, and the size of the original image is used to limit it. Since I process each sub-block as a new image, rect2 is where the sub-block's processing results in the new image are located and used to compose the final image.
Finally, the specific creation of thread destruction, resource allocation and recycling, thread synchronization and communication, will not be discussed in detail. Only discuss how the multi-threaded work is coordinated here. Since the thread that calculates the sub-block is only responsible for processing the sub-block, it also needs someone to do the sub-block partitioning, allocate data to the sub-block calculation thread, and so on. Originally should draw the flow chart, it is too lazy to draw, here briefly describes how several threads coordinate work, it is actually very simple. Interface thread A handles the interaction with the user, accepts user commands, and sends a computation message to thread B. Computation coordination thread B accepts the message of A, partitions the sub-blocks, allocates the sub-block data, and creates a sub-block computation thread Ci. The sub-block calculation thread Ci is in charge of the sub-block calculation and sends a processing result (success or failure) message to the thread B or A. The interface thread A receives the sub-block completion message, and can immediately display the sub-block processing result. Of course, it can also do nothing and wait until all the sub-blocks are processed and displayed again. Coordinating thread B receives the i-th sub-block completion message, reclaims the resources allocated to thread Ci, and destroys Ci. If all Ci have completed the work, B sends the image processing completed message to A, and A can then do the follow-up work. Here a thread B is used alone to do the sub-block calculation coordination work, and it feels more clear. Of course, interface thread A can also be used to do this work, and the coordination workload is not so great, so that B thread may not be needed.
Single-threaded and multi-threaded processing time comparison
The multi-threaded processing speed certainly cannot be simply N times the single-threaded processing speed, which is only an ideal situation. Due to a lot of extra work (thread overhead, preparation of data for each thread, synthesis of processing results, synchronization between threads, partial recalculation of the image sub-block combining section), multi-threading cannot achieve an ideal situation. The following table lists a 24bit image of 2400x1350 size divided into 12 sub-blocks, processed on an I5 4300U (dual-core four-threaded) notebook and an I5 6500 (four-core, four-threaded) desktop, to process Gaussian blur. The average time. The Gaussian fuzzy algorithm is a simple two-dimensional calculation of the direction of the row and column, with a radius of 50. In my test, the processing result of the block was also displayed in real time, and the speed may be slower.
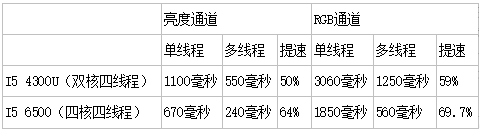
In an ideal situation, four threads can spend up to 75% less time, which is definitely not achieved. On the dual-core, four-threaded platform, the processing of the luminance channel, multi-threading reduces the time (50%) compared to a single thread. For RGB channels, multithreading is about 59% less time-consuming than single-threaded. On a quad-core, four-threaded platform, multi-threading reduced time by 64% and 69% in the luminance channel and RGB channel processing, respectively. As you can see, the speedup of multithreading is still quite noticeable. The effect of ultra-threading in the toothpaste factory is still quite alarming, otherwise the time-consuming reduction on a dual-core CPU is unlikely to exceed 50%. Of course, the number of physical cores is even more important.
But also can see a phenomenon, under the single-threaded processing, RGB three-channel processing time-consuming brightness channel processing takes 3 times slightly less, about 2.8 times (brightness channel also includes some conversion between RGB and brightness Extra calculations). In multi-threading, the processing time of RGB three channels is much less than three times the brightness of one channel processing time, which is about 2.38 times. Compared to single-threaded, it saves more time. This is because RGB processing is also handled in one thread of a sub-block, without adding new thread overhead. Therefore thread overhead is also a factor that must be considered and cannot be ignored.
Iget Legend,Iget Legend Puffs,Iget Vape,Disposable Iget
Shenzhen Zpal Technology Co.,Ltd , https://www.zpal-vape.com